Performance & Tracing Update

High level summary
- Benchmarking: We've performed benchmarks and analyses for Node versions
8.9.2and8.10.0. - Development: Design phase for implementing quick queries in the analysis pipeline has begun.
- Workbench: We're finishing up the new features for the reporting pipeline; Haskell profile definition work is ongoing.
- Tracing: Improving the Prometheus output is ongoing; the node's build info will be accessible as a Prometheus label.
- UTxO Growth: Our tooling has been augmented to support benchmarks starting with a non-empty chain.
Low level overview
Benchmarking
We've performed a full set of release benchmarks for Node 8.9.2. Comparing with release 8.9.1, we could not detect any performance risks for that version.
The benchmarks for 8.10.0 have shown a slight improvement in the time the block forging loop needs to evaluate, whilst additionally, resource usage of the cardano-node process was also slightly reduced - a nice performance improvement.
Development
Our analysis pipeline is based on batch analysis of data from over 50 cluster nodes; it consumes very large amounts of trace output ex post facto, when the actual benchmark has terminated. This is very time-intensive, and not viable for obeserving an additional metric that you later on determine might need consideration.
We're planning to add quick queries into a benchmarking run's trace data to our analysis pipeline. These will be structured such that parameterizable, ad-hoc querying is supported. Initial tests showed that evaluation speed of such queries is fast enough to merit designing a principled, and generalized, syntax for them - and a subsequent implementation.
Workbench
The reporting pipeline has been augmented with direct support for customizable, and stylable, TeX rendering - currently receiving final touches.
Porting our performance workbench's profile definitions to Haskell, and providing them with an appropriate test suite, is ongoing work. It is our goal to both increase reliable profile definition and validation, and facilitate usage by engineers less familiar with the workbench.
Tracing
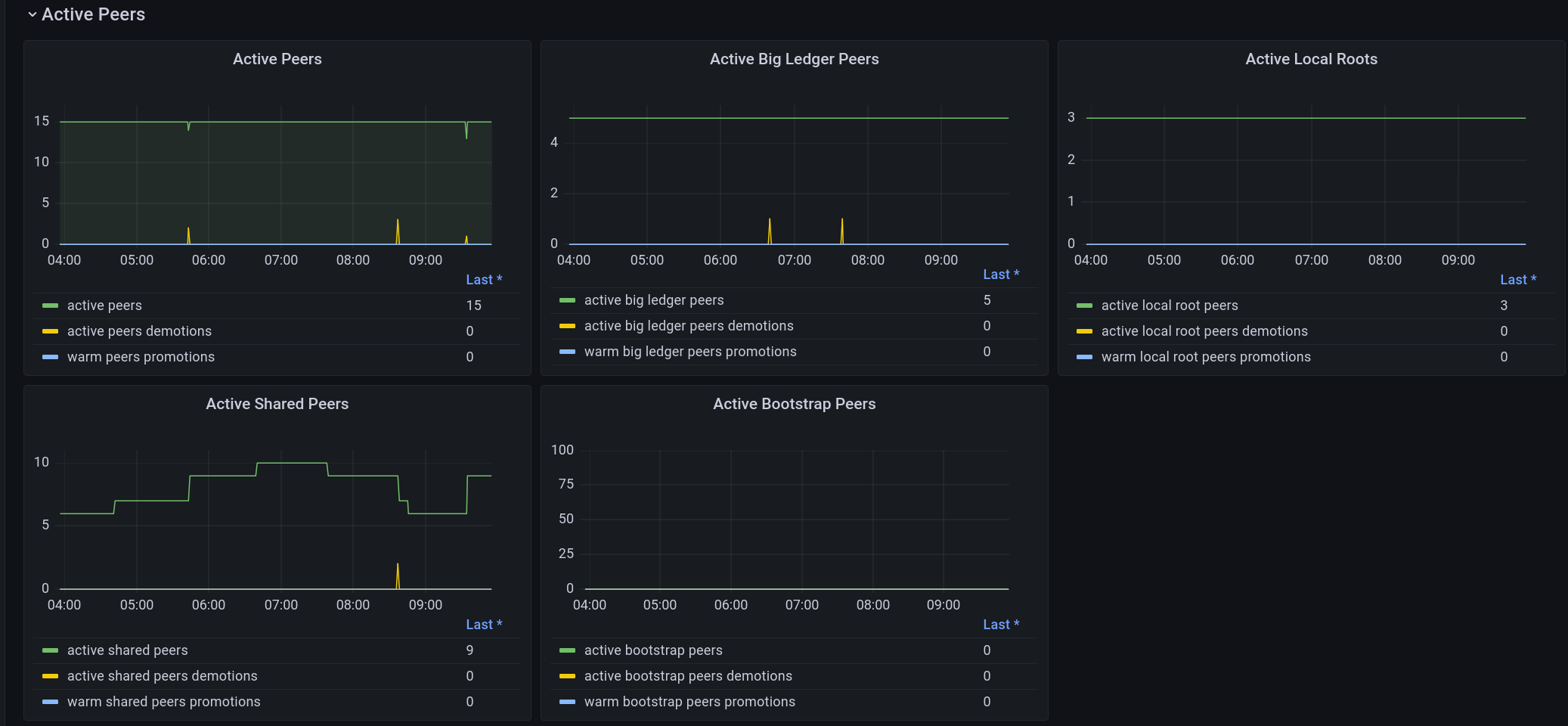
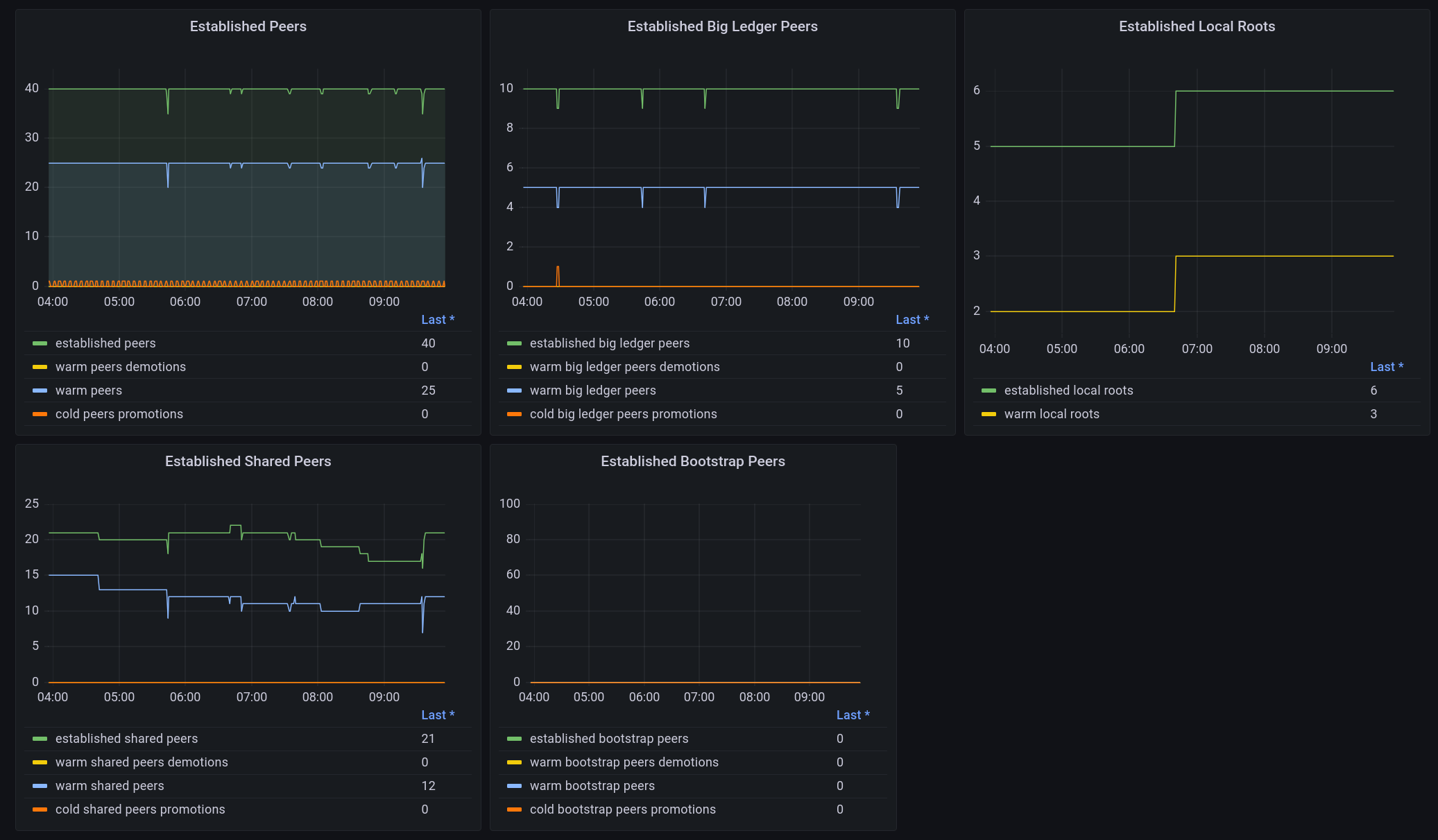
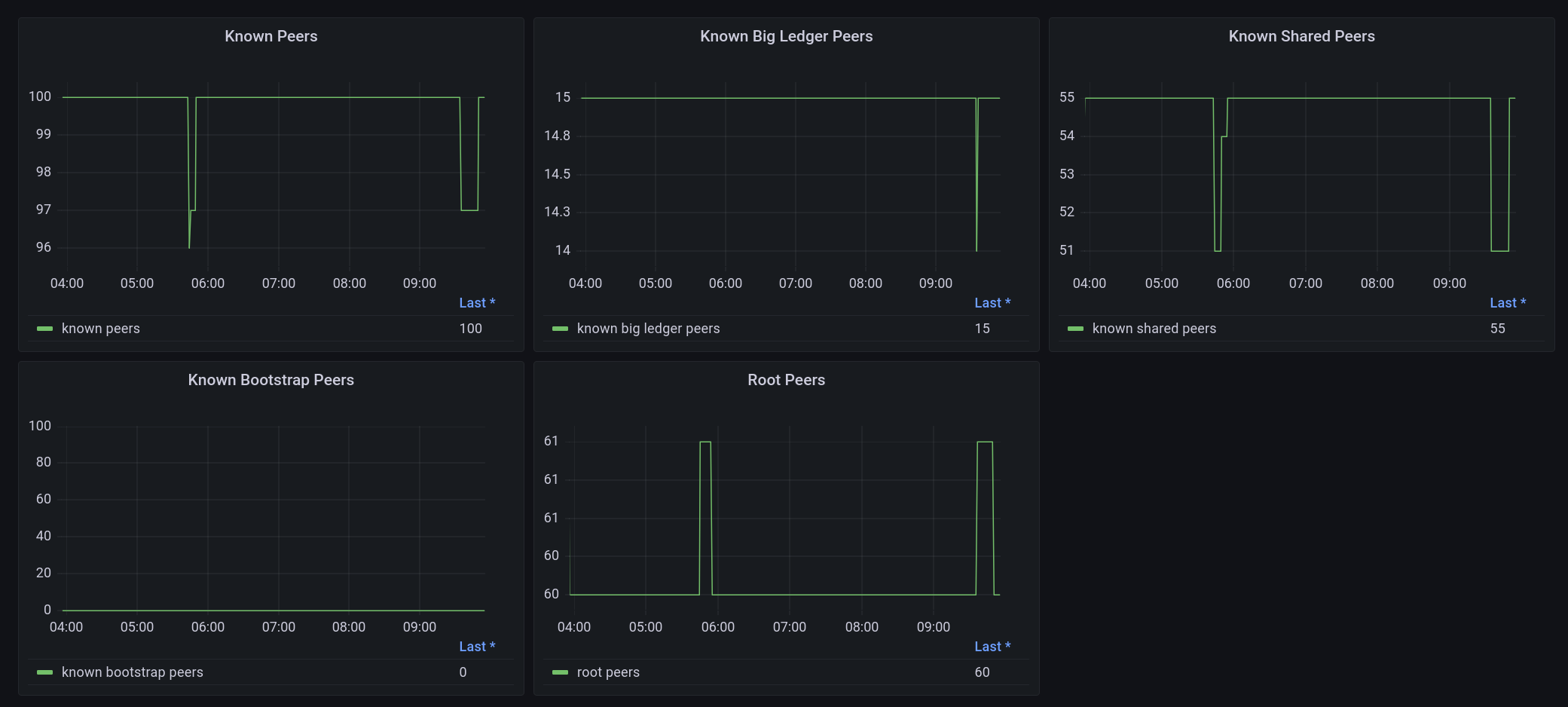
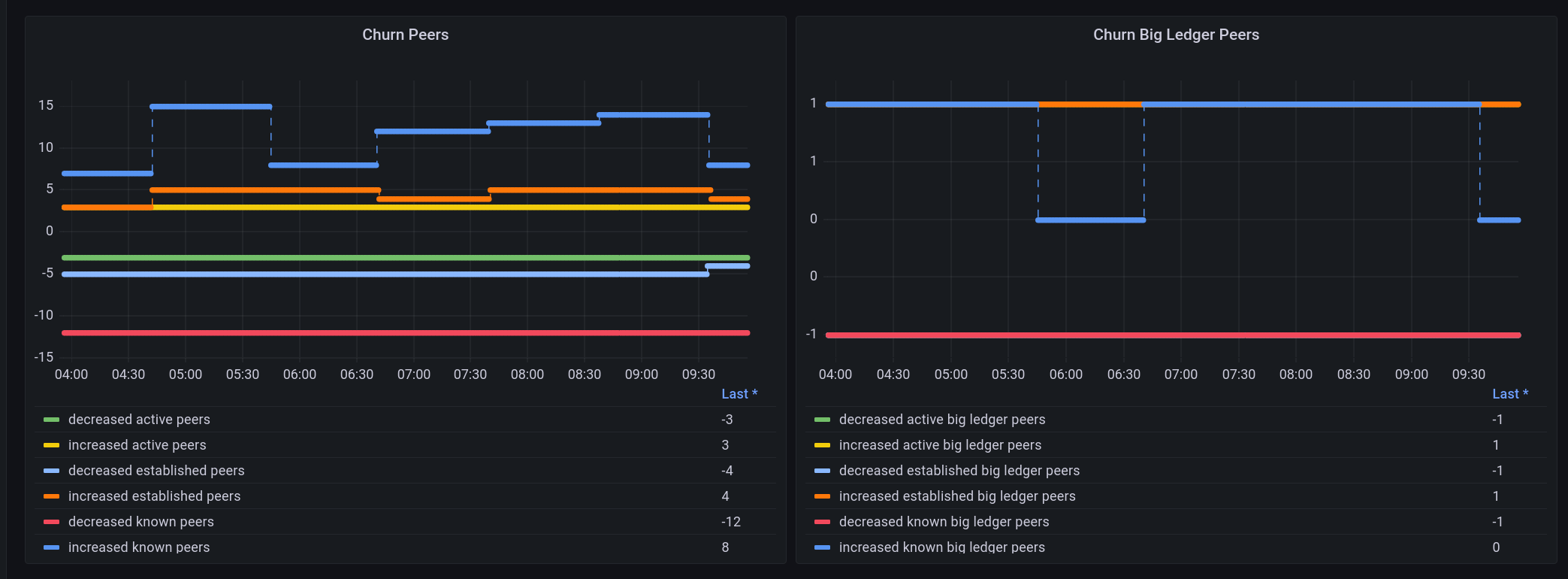
The work to improve system metrics as presented to Prometheus is still ongoing. Type annotations, as well as introducing Prometheus labels for certain metrics to convey (like e.g. build information), will make that interface more versatile. It also facilitates configuration of monitoring or dashboards like Grafana on top of those Prometheus metrics.
UTxO Growth
For the UTxO scaling benchmarks, we've augmented the workbench with the capability to support injection of a custom synthesized chain into the deployment, and start a benchmark only after replaying that chain - whereas our benchmarks usually start just with a genesis block.
To achieve that, different components of our tooling needed addition of features: distributing that chain to the node cluster, having analysis work without necessarily providing trace evidence of each block in the chain being forged by a benchmarking node. Cluster timing had to be adjusted to account for the gap between genesis start time and the chain tip. However, this entire mechanism opens up the possibility of having a very distinct ledger state at hand for a benchmark - one, that's been particularly crafted via a series of pre-defined transactions constituting the blocks during creation of the synthesized chain.
In the future, we plan to flesh out a more general design of that mechanism, which currently is tied to a very specific use case only.